-
Tier IV Bus Deployment
Summary
Tier IV Automated Driving System (ADS), enabled through Autoware, an open-source software for autonomous driving, was tested and deployed at HORIBA MIRA’s proving ground at MIRA Tech Park. The demonstration explored and validated Level 4 autonomous operation in both simulation and real-world conditions, in compliance with UK road rules and regulations.The work packages primarily included mapping the proving ground route, sensor calibration, planning simulations, and physical testing. A UK compliance assessment for Tier IV was conducted using both simulation and real-world test data.

Tier IV & HORIBA MIRA Autonomous Bus Deployment
Deliverables- Vector Map Building
- Vehicle Instrumentation & Sensor Calibration
- Risk Assessment
- Scenario Based Testing (simulation & real-world)
Project Website -
CERTUS
Summary
CERTUS introduces a step change in safety assurance processes to reduce the test burden and accelerate scenario coverage, whilst also complementing existing data generated using traditional methods through multi-pillar testing and proprietary test oracles. This project involved the development of tools and algorithms necessary to design the most efficient method for evaluating the automated driving system, including a mixed reality platform that integrates physical testing with virtual scenario modeling.

CERTUS - Accelerating Autonomous Vehicle Validation
CERTUS Features- Multi-Pillar Testing
- Proprietary Oracles
Project Website -
ADAS Post-Processing Tool
Summary
Development of ADAS post processing tool to analyse data from standardised test like EURO NCAP for Level 2 Autonomous Systems (Automatic Emergency Braking, Lane Keep Assistance, Adaptive Cruise Control, etc.).

ADAS Testing
ADAS Tool Features- Test Scenario Detection
- Data Analysis
- Report Generation
Project Website -
VeriCAV Lite Enhancements
Summary
Enhancement of VeriCAV Lite, a web application built with Python to create test cases. The application developed greatly reduce the manual effort in defining test scenarios. The application allows for scenario parameters definition along with conflicts. The application then provides all test cases considering scenario parameter and conflict defined.
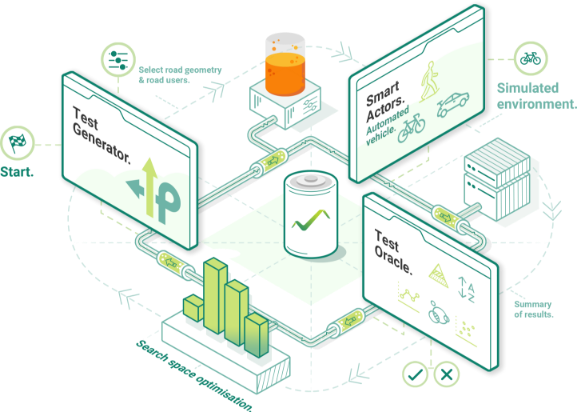
VeriCAV
VeriCAV is a modular and flexible platform to allow automated vehicles to be efficiently tested in simulated environments. VeriCAV automates the process to generating and analysing complex driving scenarios populated with other Realistically-behaving road users.
Features- Test Generator
- Test Oracle
Project Website -
A Unified Motion Planning Algorithm for Autonomous Vehicles in Urban Environments
Abstract
This study aims to develop a unified motion planning algorithm for autonomous vehicles to navigate urban environments following traffic rules. A hierarchical motion planning framework divides the workload of navigating a vehicle to a destination through a structured road network. Mission planning uses A* search with distance heuristics to find the global route. A rule-based behaviour planner makes decisions considering traffic rules and obstacles, setting a goal state for the local planner. The local planner generates paths to reach the goal state, generating kinematically feasible and collision-free paths using polynomial spiral optimisation and circle-based collision checking algorithms. The velocity profile generation method generates the trajectory according to selected behaviour providing waypoints and velocity at each point along the best path to be followed by the vehicle control module. The developed framework was verified and validated using the Carla simulator for various urban scenarios making improvements to the baseline implementation. The study also explores the importance of interaction between behaviour and the local planning layer, which could be improved by providing a feedback loop for handling undesirable situations.

Urban Driving - Avoiding Static Obstacles
Cranfield University - Connected and Autonomous Vehicle Engineering - Individual Research Project
Steps Involved- Mission Planning using A* Search
- Rule Based Behaviour Planning
- Polynomial Spiral optimisation for local planning with velocity profile generation
- Verification and validation using Carla Simulator
-
Autonomous Navigation on an Unmapped Track/Road
Summary
This work aims to solve the unmapped autonomous navigation problem in a semi-structured environment defined by coloured cones, using a stereo camera only. Different tasks have been considered in the development process to achieve this aim, including camera calibration, cone detection, pedestrian detection, stereovision, path planning, path following, and simulation verification & validation. The methodology and results analysis of each task is analysed. As a result, the software has been developed to control the vehicle to operate in such a scenario. At the same time, some future works remain to be solved, including the implementation of pedestrian detection in path planning, etc
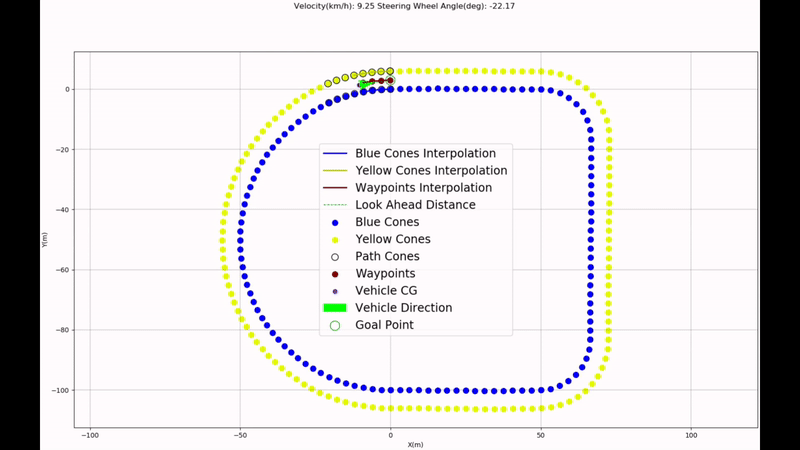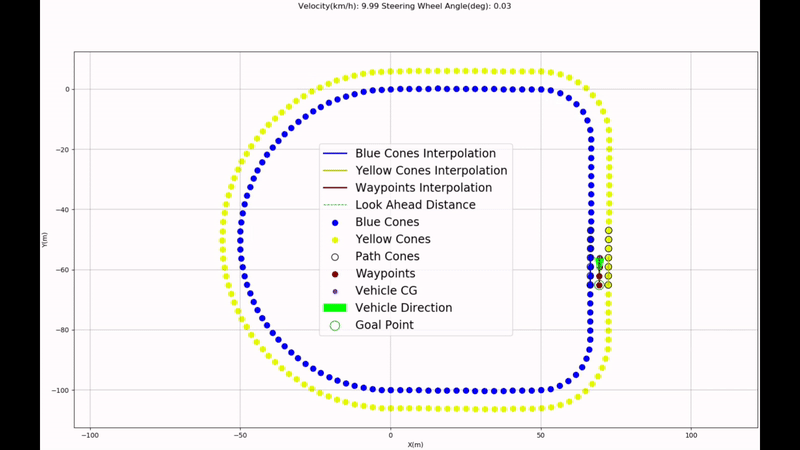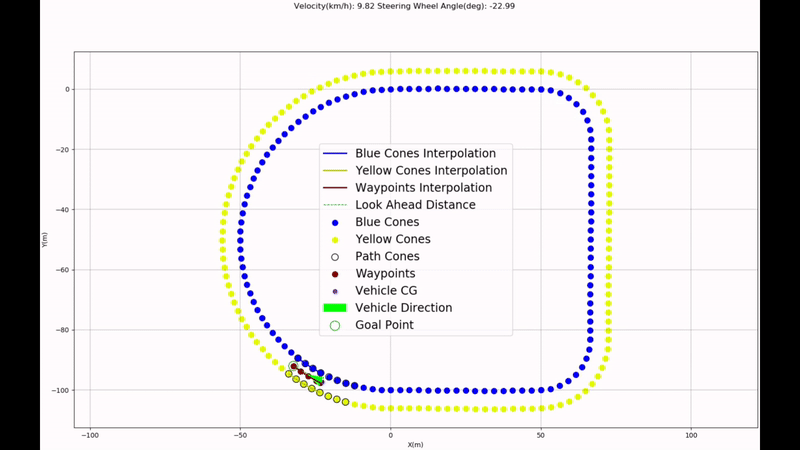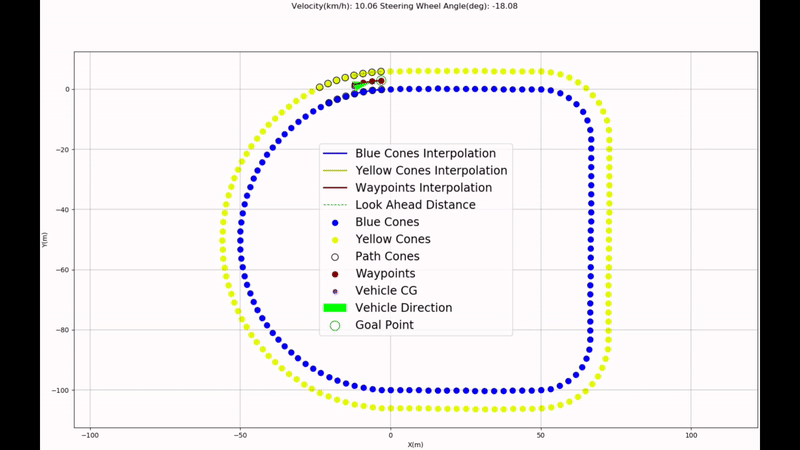
Autonomous Navigation of Vehicle on unmapped track/road using Python and ROS
Cranfield University - Connected and Autonomous Vehicle Engineering - Group Design Project
Steps Involved- Camera Calibration
- Cone and Pedestrian Detection
- Stereo Vision
- Delaunay Triangulation for path planning and Pure Pursuit for path following
- Verification and Validation using Carla Simulator
-
Human Factors Evaluation of the Tesla Autopilot System
Summary
For this study, the data was collected by taking a test drive in Tesla Model Y. The drive was carried out with manual and autopilot mode sessions with a secondary task and talking with the passenger. The secondary task requested was to control the air conditioning inside the vehicle, along with some questions for knowing drivers' understanding and opinion of the vehicle and autopilot system. Eye and face tracking will be carried out using Python, OpenCV, and open-source code for Gaze Tracking. Eye-tracking was performed by pupil detection and tracking to find the viewing direction and blink count. A telematics app freely available on both iOS and Android platforms, AutoBeacon, was used to capture the driving behaviour during the test drive. The application detects driving activity automatically and starts collecting IMU and GPS data. The data collected during the drive will be processed after trip completion, giving insights about the drive with alerts regarding overspeeding, acceleration, braking, cornering, and distracted driving using a phone, if any. The heart rate distribution in BPM collected using a given device was computed by finding the mean, median, and standard deviation during various activities carried out during the drive. Python was used for data analysis and visualisation. The driving scene in front of the vehicle was analysed using algorithms developed using python, TensorFlow models for object detection, and tracking using a concept like CSRT Tracker. The distance from the vehicle to objects will be estimated using monocular depth estimation and analysed to investigate the driving behaviour across various activities.
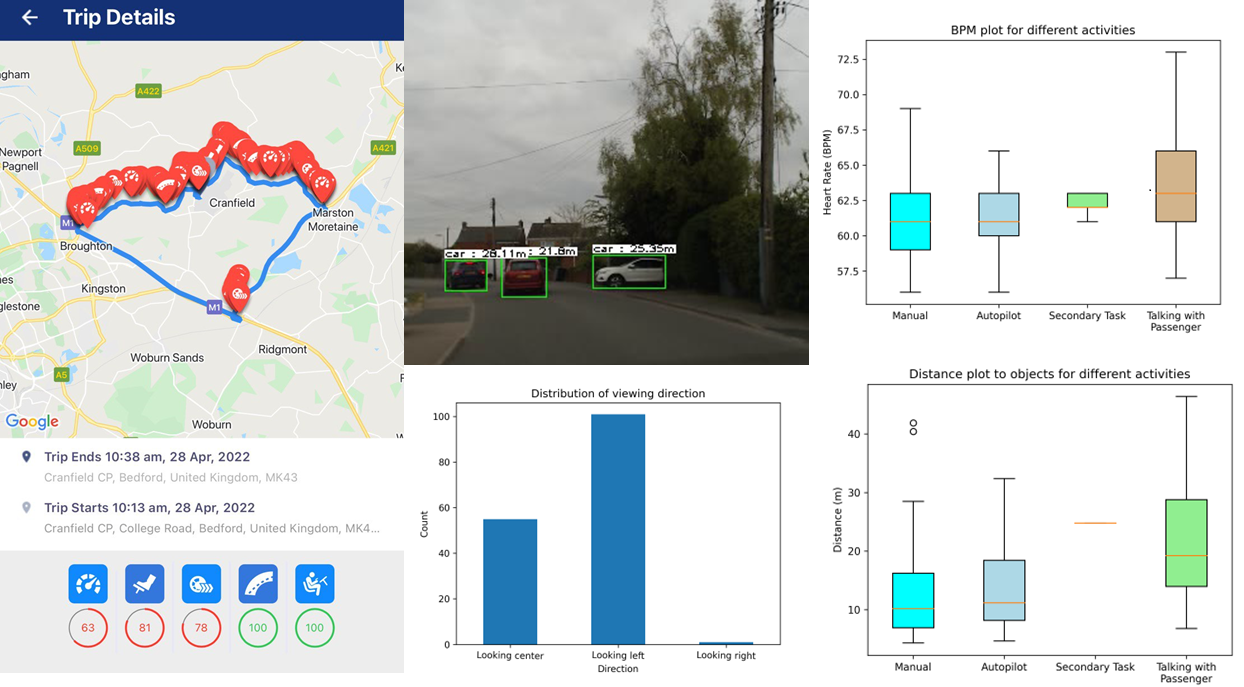
Human Factor study on Tesla Autopilot
Cranfield University - Connected and Autonomous Vehicle Engineering - Human Factors, Human-Computer Interaction and ADAS Systems
Steps Involved- Eye and Face Tracking
- Driving Behaviour using Telematics Application
- Heart Rate monitoring
- Driving Scene Assessment using dashboard camera and computer vision
-
Dubins Path Planning and Carrot Chasing Algorithm
Summary
Dubins path planning algorithm was generated using a geometric approach. The Carrot Chasing Algorithm (CCA) will be used to follow the path generated by the Dubins path planning algorithm, as shown in the previous section. CCA sets a virtual target point (VTP) on the desired course. The vehicle heading direction will be corrected at each step to reach this point.
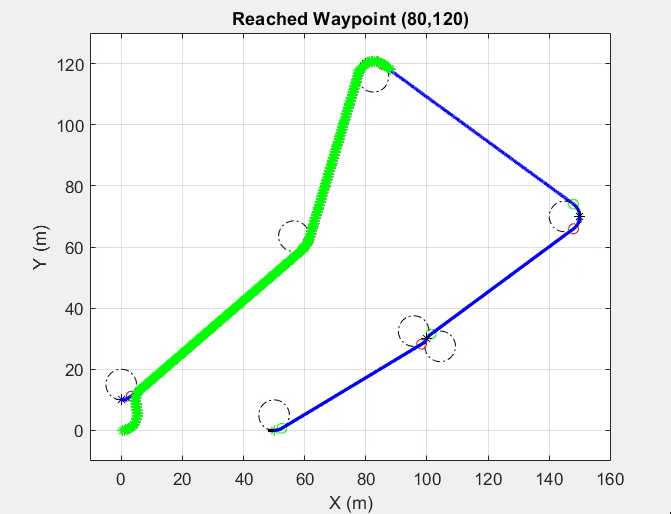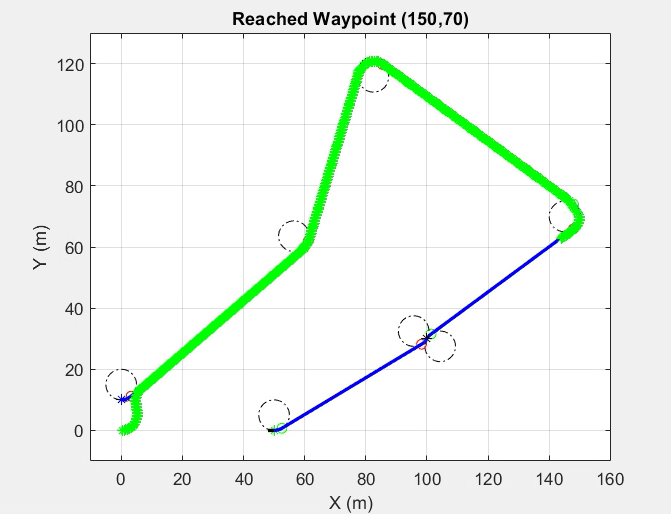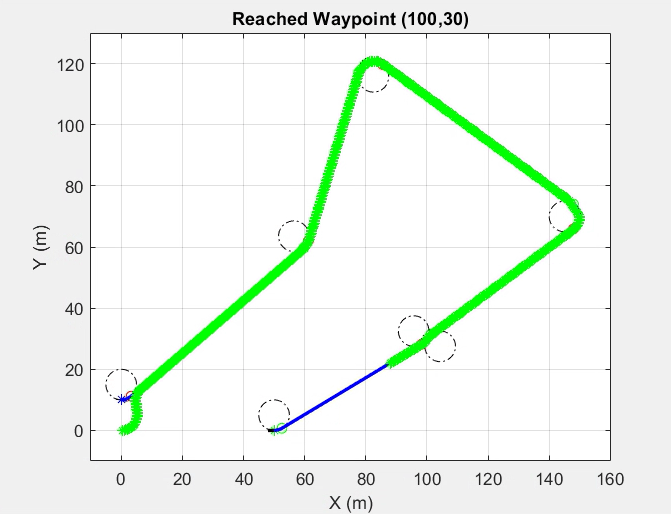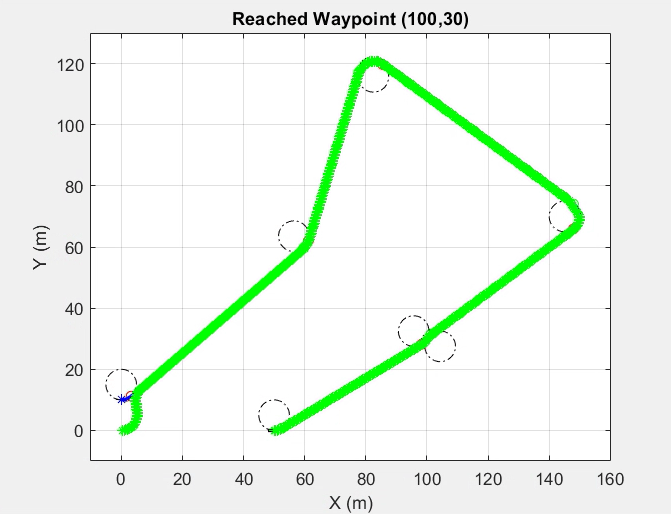
Path planning using Dubins Path and following using Carrot Chasing Algorithm
Cranfield University - Connected and Autonomous Vehicle Engineering - Path Planning, Autonomy and Decision Making Assignment
Steps Involved- Path planning using Dubins Path Algorithm & geometric approach
- Find shortest path
- Carrot Chasing Algorithm reducing cross-track error
- Guidance command generated using virtual target point and heading angle correction
-
Simultaneous Localisation and Mapping
Summary
This work designs a simultaneous localisation and mapping (SLAM) using Kalman and Particle Filter. A correction step follows the prediction step. The study also considers bearing only and range only measurements, comparing the performance of the SLAM algorithm developed. Later Extended Kalan Filter (EKF) is implemented, enhancing the existing SLAM algorithm using KF and PF.
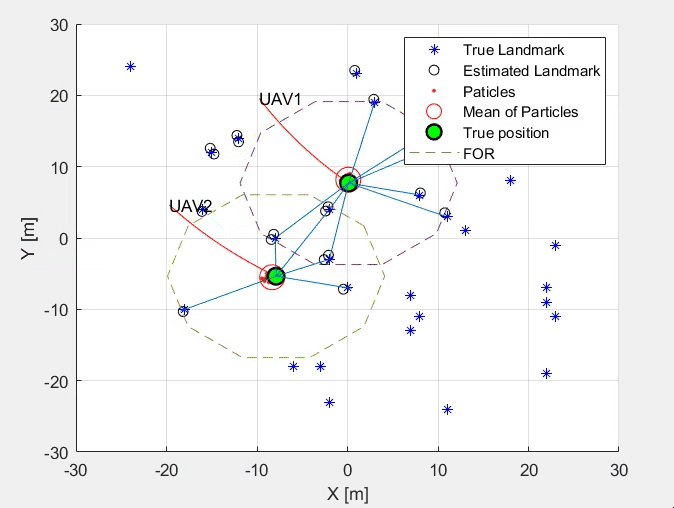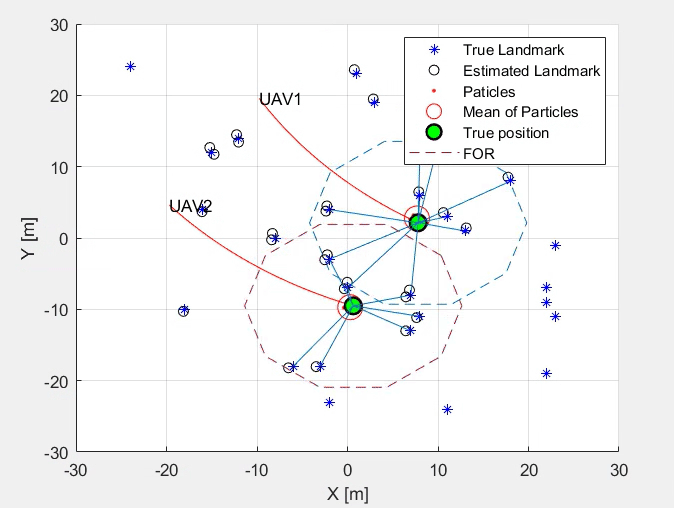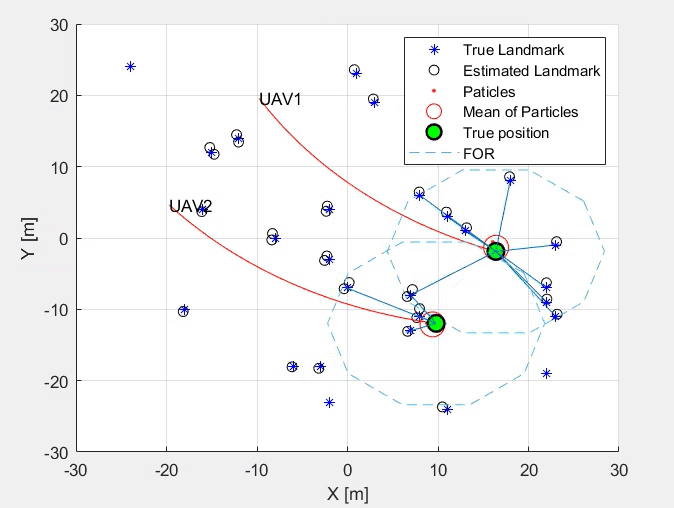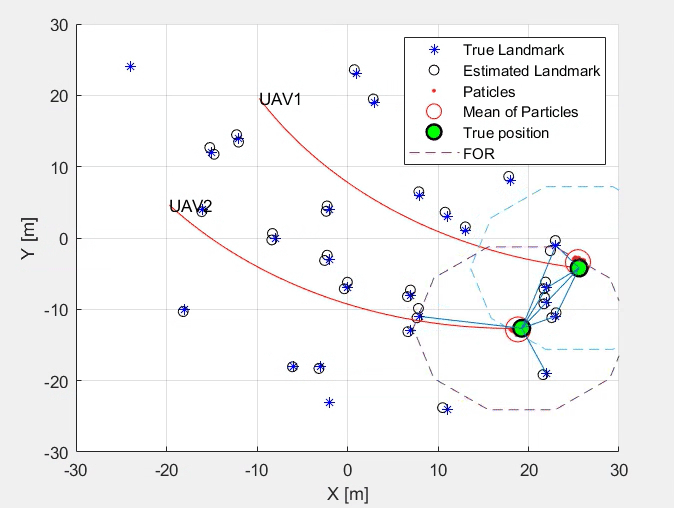
Simultaneous Localisation and Mapping using Kalman and Particle Filter
Cranfield University - Connected and Autonomous Vehicle Engineering - Path Planning, Autonomy and Decision Making Assignment
Steps Involved- Prediction Step
- Correction Step
- Kalman Filter
- Particle Filter
-
Business Model: Robotaxi
Summary
This group work aimed to analyse the current robotaxi's blue-ocean market strategies and enablers. In the first session, we focus on a high-level view of the existing industry; two analysis tools are used in various factors and competitive dynamics studies. Disruptive technologies are probed with a state-of-art view of autonomous driving and optimization methods in the following sessions. Moreover, we introduced the influence of the key technology enablers in economic, social, safety, and legal aspects, respectively. Finally, critical research in the corresponding business model and strategy is generated in the last session, including a complete view of recommended strategies and an objective possible risk study.
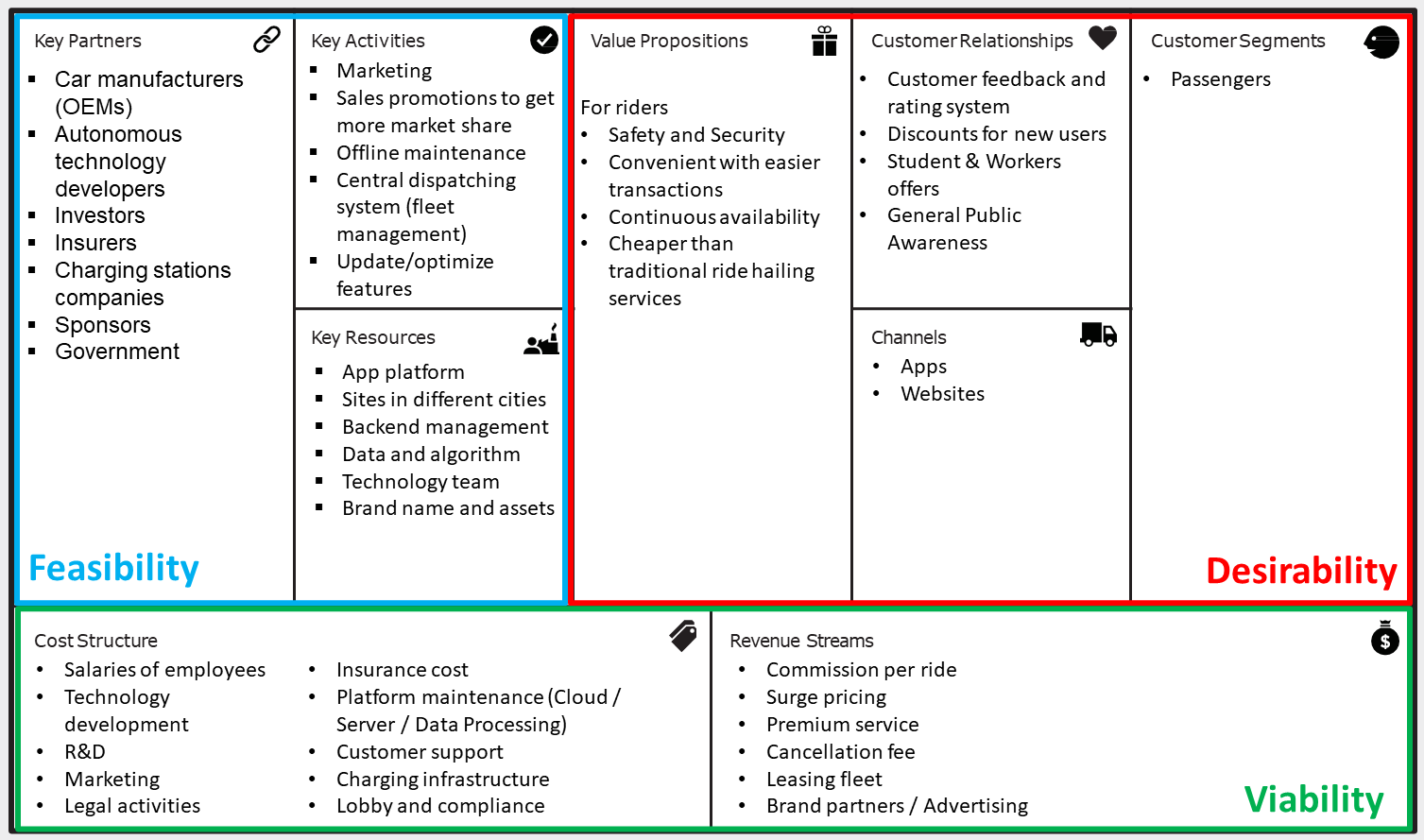
Business Model Canvas - Robotaxis
Cranfield University - Connected and Autonomous Vehicle Engineering - Technology Strategy and Business Models Assignment
Steps Involved- Industry Analysis and Competitive Dynamics
- Identification of disruptive technology and competitive position of industry incumbents
- Business Model and Strategy
- Risk assessment and countermeasures
-
Applications of Optimisation Techniques in Transport Systems
Summary
This research-based coursework aims to present optimisation techniques in motion planning for connected and autonomous vehicles. Various state-of-the-art methods involved in the motion planning of CAV was identified and investigated. Optimisation techniques discussed here can be mainly classified into classical, bionic and machine learning methods. Some of the optimisation techniques found were briefly described, along with their objective function, constraints, and boundary conditions. An outline model was designed using an open-source traffic simulator and RL agent in python. The study also depicts the challenges motion planning architectures face and the drawbacks of different optimisation techniques.
Motion planning using highway-v0 environment
Cranfield University - Connected and Autonomous Vehicle Engineering - Transport Systems Optimisation Assignment
Steps Involved- Motion planning for autonomous driving in highways
- Implemented in python using optimistic planning of deterministic systems and RL agent Deep Q-Network (DQN)
Github -
Lane Departure Warning System
Summary
This work aimed to study and understand the lane departure warning system while going through implemention and development of sensors and perceptions for the system. A systems engineering approach was taken to understand the system requirements, use cases, and validation strategies. Also identified key technology enablers for the system. The system concept was designed in Python using libraries like OpenCV and NumPy. The system designed accepts image, which is processed to detect road lane using filtering, thresholding and perspective transform. The road curvature and road type is estimated by fitting the lane detected to a second-order polynomial. The vehicle's position with respect to the lane is determined, and a lane departure warning is given if the vehicle goes outside the threshold set for offset from the lane centre.

Lane Departure Warning System
Cranfield University - Connected and Autonomous Vehicle Engineering - Sensor, Perception and Visualisation Assignment
Steps Involved- Lane detection / tracking
- Lane status anlysis
- Lane augmentation
Github -
AutoBeacon: Smartphone based Driving Behavior Monitoring
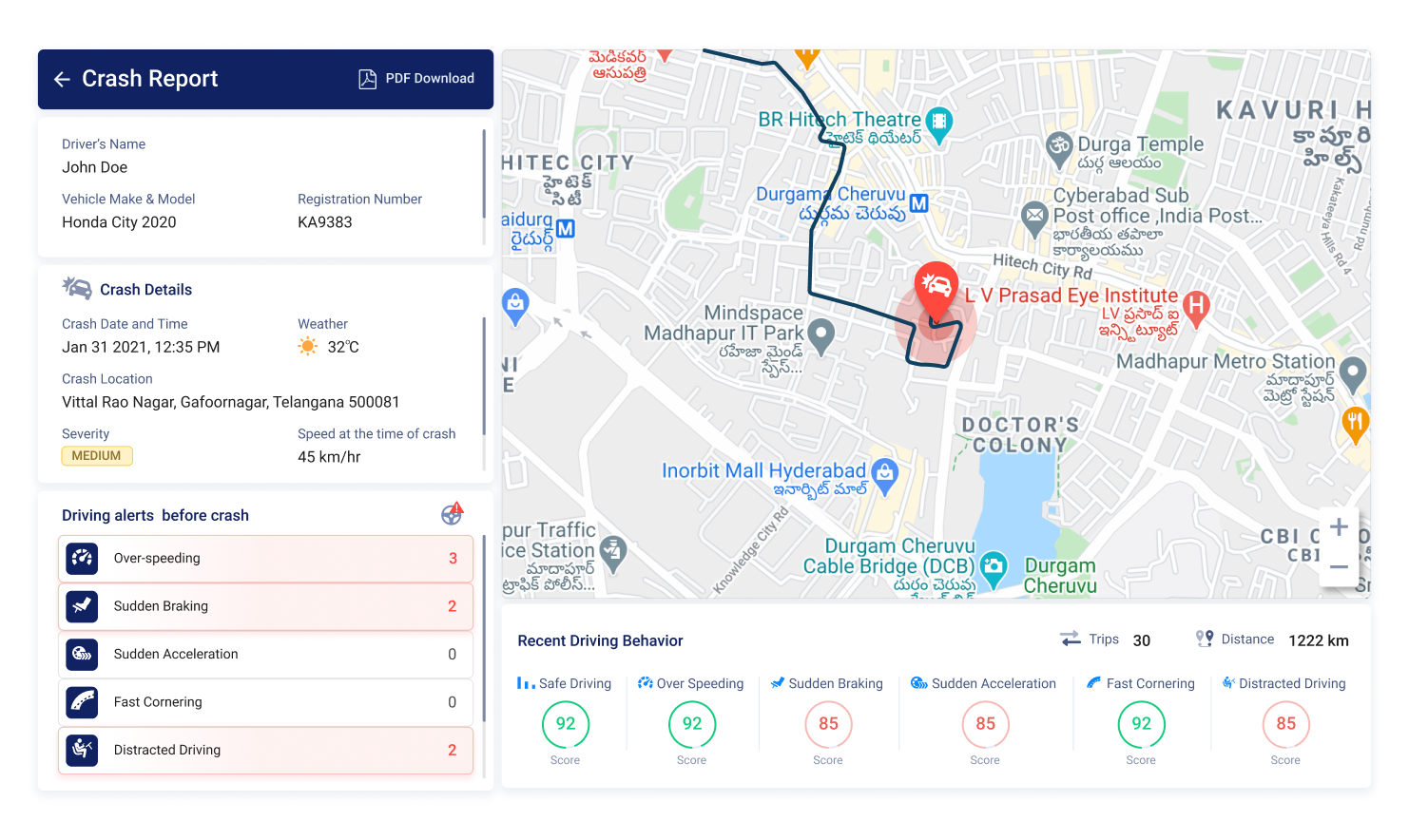
Crash Detection
A phone based driving behaviour detection application for android with real-time crash detection
Features- IMU and GPS data collection
- Real-time Crash Detection
Project Website -
Vehicle Inspection using OBD-II PID Data
Summary
Vehicle Inspection reports are generated from PID data collected for each vehicle for a fixed period, say a month. The supported PIDs for each vehicle will be different, so initially, the supported PIDs by each vehicle are collected, and then the PID config for vehicle inspection will be generated. The significant PID used for inspection is categorised into primary and secondary. The primary PIDs are the default ones required for the proper functioning of the telematics device. The secondary PIDs are further classified into two depending on their state being a dynamic or static nature. Then the PID config files are generated, which will have the primary and secondary PIDs required to collect data for vehicle inspection. Most of the vehicles will have more than one config file so that we need to rotate PID config files during the period of inspection. The rotating of PID config files is based on their importance and the amount of data required for running the vehicle inspection algorithm. Each trip across the inspection period will be inspected, and a weighted average on distance traveled will be considered an overall rating for the vehicle during the period. Along with PID data, DTC data is also collected for the period to show vehicle owners various defects detected by vehicles for better maintenance. The battery voltage data is also collected during the period, and battery ratings are given based on the voltage post-trip. The vehicle inspection provided ratings and details about fuel economy, battery voltage, max power and torque achieved, idle rpm, coolant temperature, engine load distribution, charging system (alternator), O2 sensors, and fuel trims, along with distance travelled for the period. Along with DTC found during the period, their severity, system info, and distance travelled with Malfunction Indication Light (MIL) ON and since clearing DTCs. The inspection report is available across the mobile application (as shown in figures below) and in the web app for fleet owners. This will give a performance, safety, and maintenance insights to customers on a regular basis for keeping their vehicle in good condition.
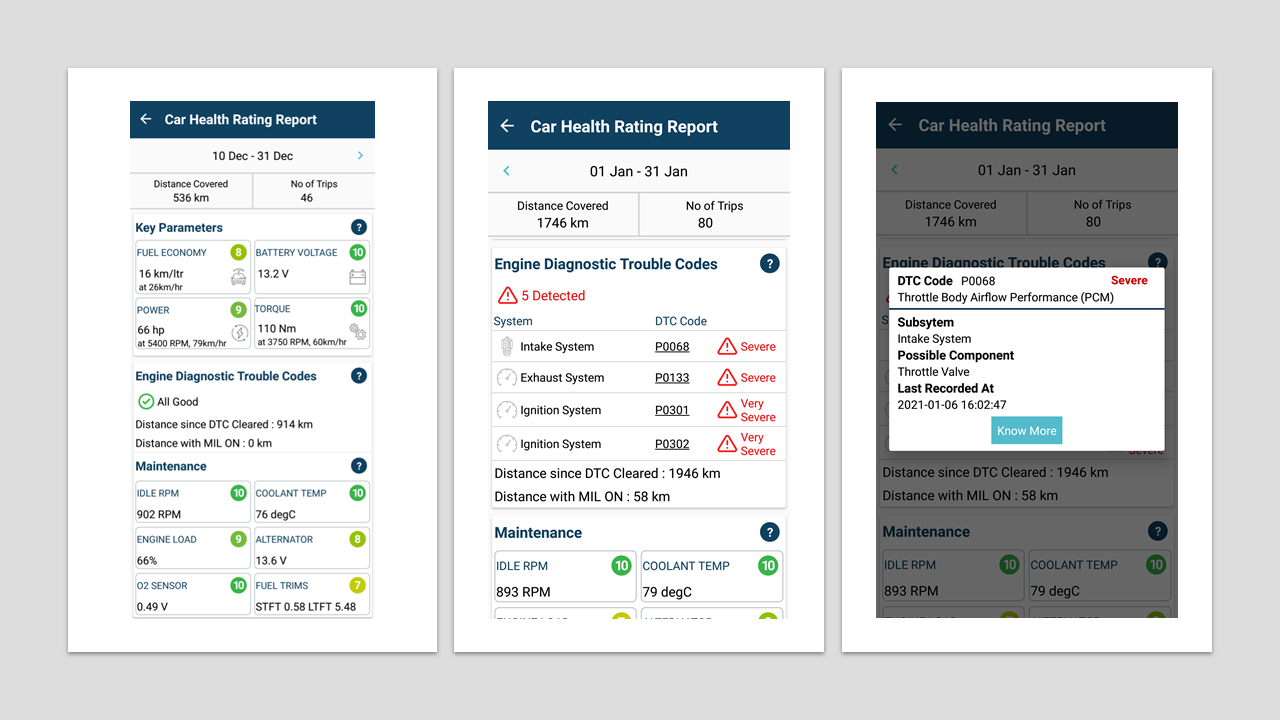
Vehicle Inspection
Vehicle Inspection using OBD-II PID and DTC data
Figures- Vehicle Inspection Report (without DTC)
- Vehicle Inspection Report (with DTC)
- DTC Info
Project Website -
AutoVision: Driving Scene Risk Assessment
Summary
The Android application captures 60 Frames during driving events like hard acceleration, sudden braking, overspeeding, etc. Later the frames are processed to detect and track interesting objects during the driving scene to find their approximate proximity to the vehicle. The frames' objects were detected using the TensorFlow lite model from this project. Interesting class objects were a car, bus, truck, motorcycle, bicycle, and person. The objects were further tracked based on a custom tracker depending on their position during the event. The user can later review events captured with information about some severity and object that came the closest. The below images shows the event captured and processed as mentioned above with details about object class and distance from the source. The second image depicts the android application review screen with vital information.
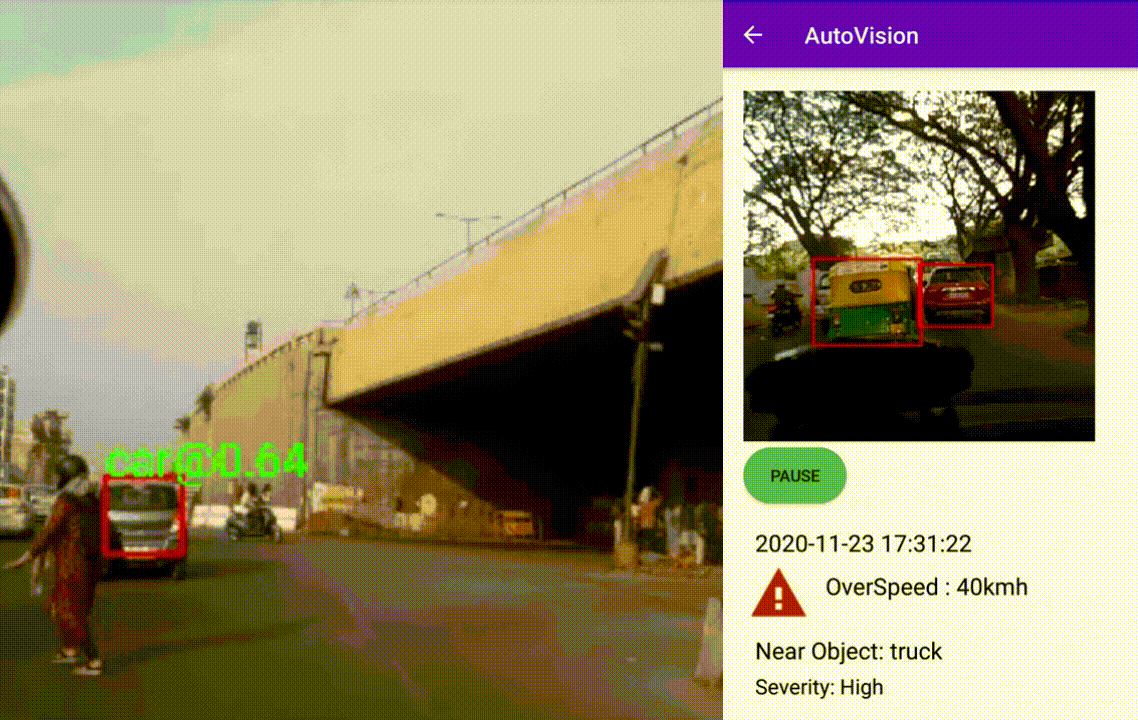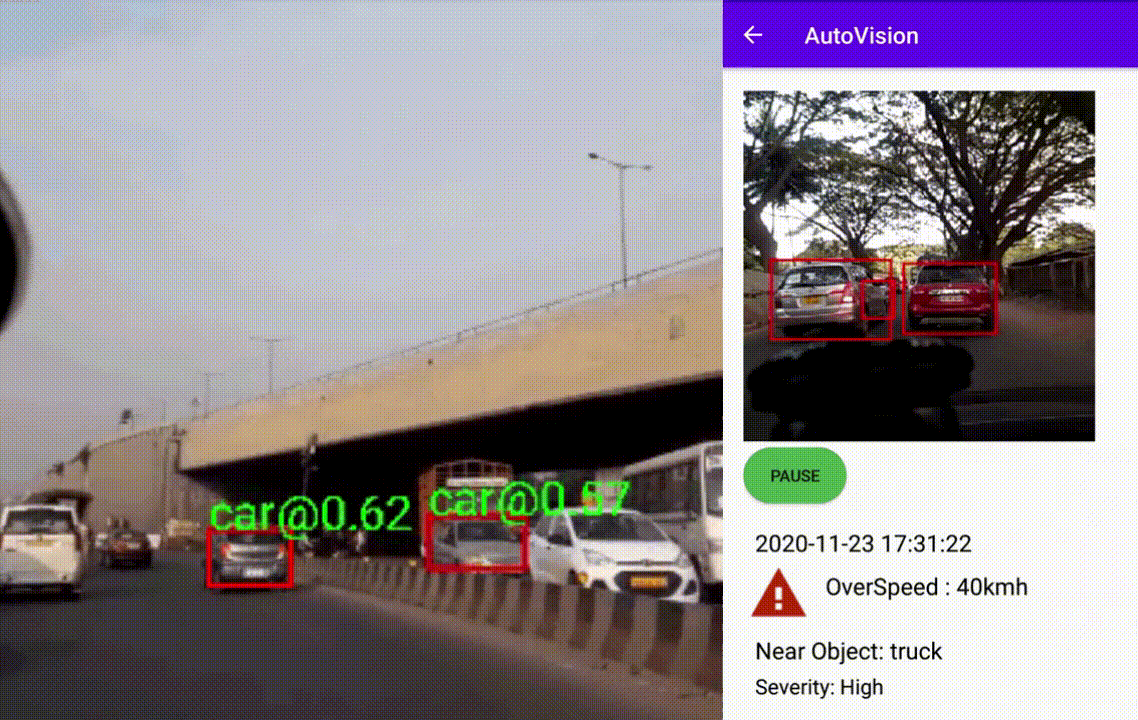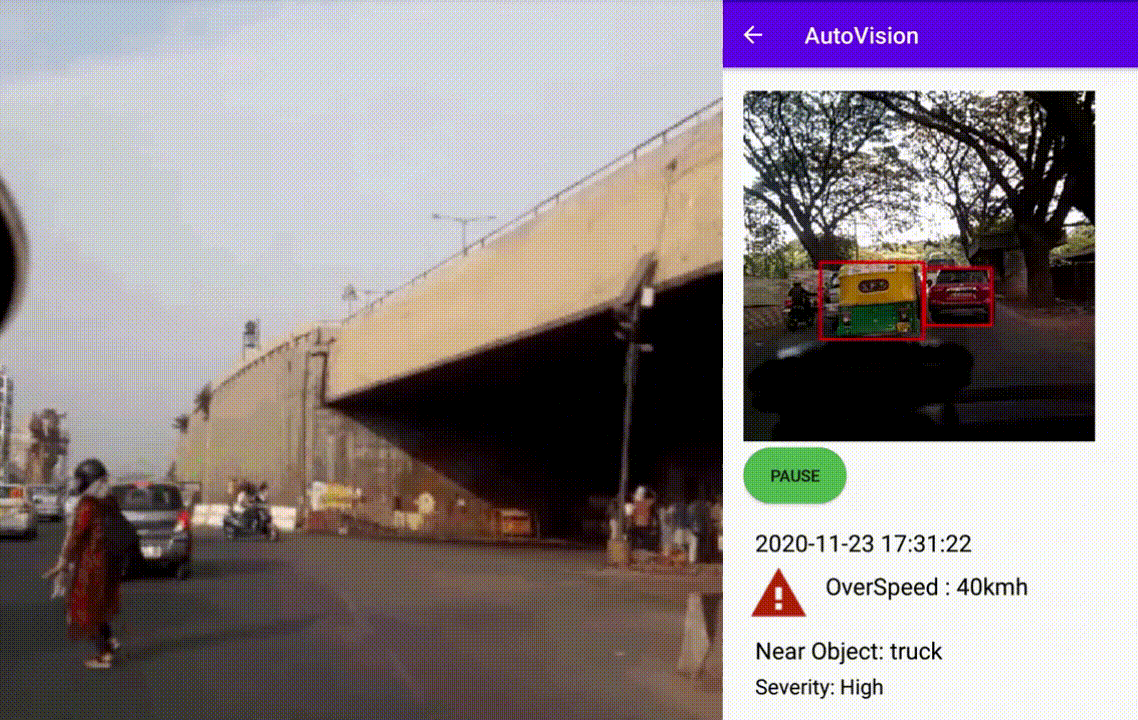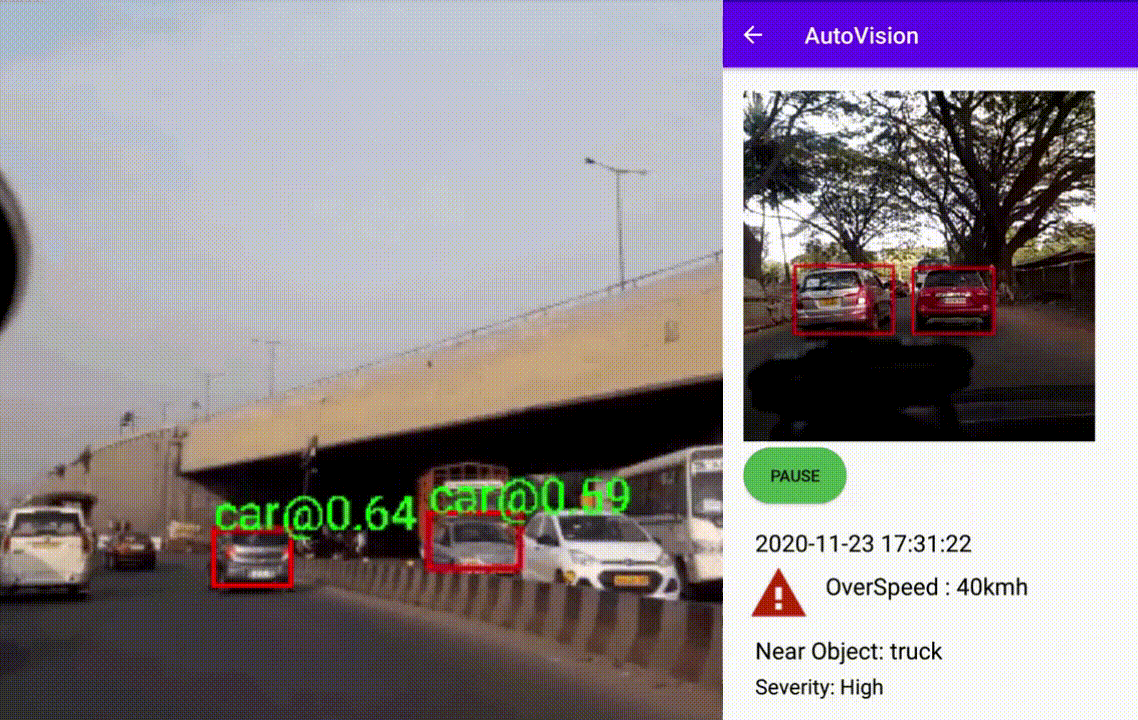
Driving Scene Assessment
An application to assess driving scene using TensorFlow Lite models
Features- Shows the event captured and processed as mentioned above with details about object class and distance from the source
- Android application review screen with vital information
Project Website -
TurboCharger Fault Detection
Summary
Detection of TurboCharger failure or malfunction using PID data and DTC info. The PID data were collected from the vehicle CAN network using OBD II protocols and telematics devices from various vehicles. The TurboCharger performance was evaluated based on the amount of pressure created inside the intake manifold using Intake Air Temperature (IAT) & Manifold Absolute Pressure or Mass Air Flow (MAF) sensor depending on their availability. The value of these quantities where further binned based on Engine RPM and MAF. Reference data for comparison were built by taking the median value for each bin collected across the same make-model, which doesn't have any DTC related to TurboCharger. The bin values' euclidean distance was taken to compare between vehicle and reference, with some threshold. The below images depicts the study carried out between reference data & defective vehicle, and the same vehicle before and after DTC occurrence.
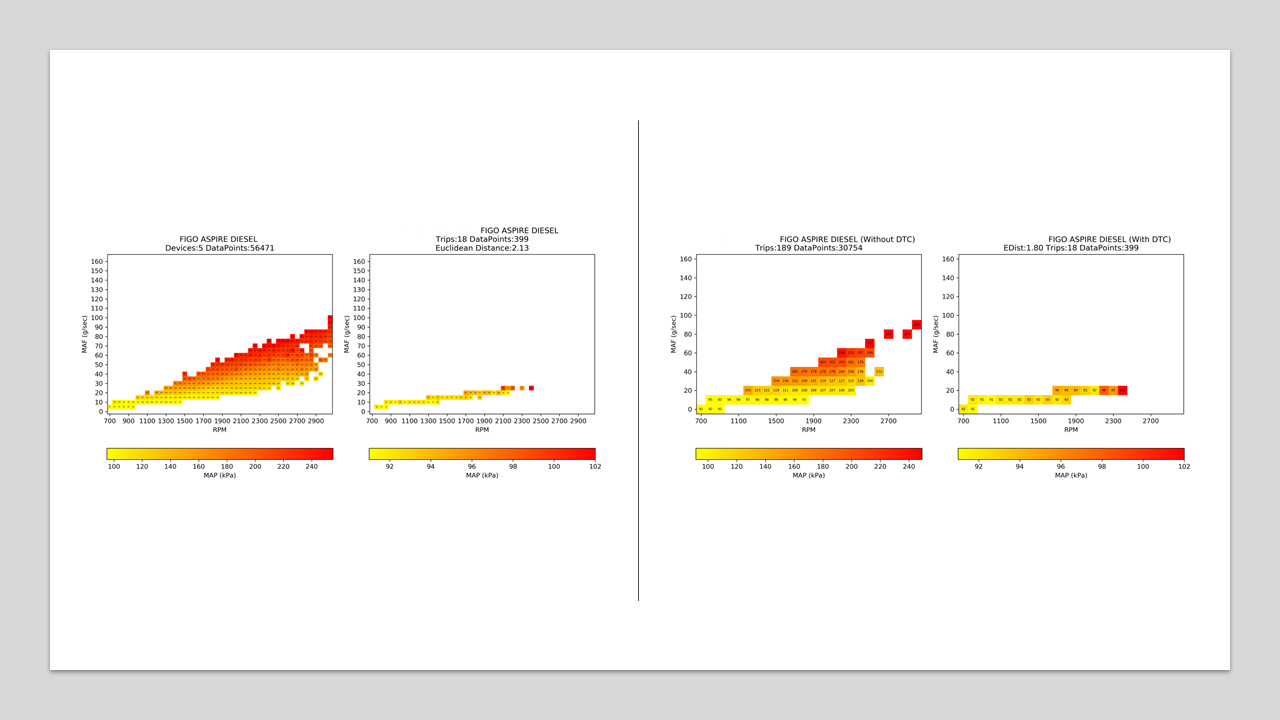
TurboCharger Fault Detection
Fault detection in turbo charger using OBD-II PID and DTC data
Figures- Cross Vehicle comparisson of Intake Manifold Pressure before and after DTC
- Cross Model comparisson of Intake Manifold Pressure across vehicle with and without DTC
-
Gear Shift Recommendation
Summary
Gear Shift recommendation for vehicle owners was provided based on their shifting behaviour using Speed and Engine RPM data. The PID data were collected from the vehicle CAN network using OBD II protocols and telematics devices from various vehicles. The speed and rpm data collected were used to find various gear ratios; these values were further binned to respective gears using the K-means clustering technique. The reference speed limits for each make-model and gears were collected from a massive dataset of speed-rpm data across various drivers. The speed limits were decided based on upper and lower percentile values across the data for respective gears. Further, the boundaries were smoothened to avoid gaps and smoother transmission. Each driver was compared across gears and respective speed limits. The instance of wrong gears was found and further classified these occurrences into acceleration or deceleration conditions. The most predominant recommendation found were provided to the customer, as shown below in Fig. Gear Shift Recommendation Card. The below also depicts the K-means Clustering technique for finding gears and representation of gear utilisation by a particular driver.
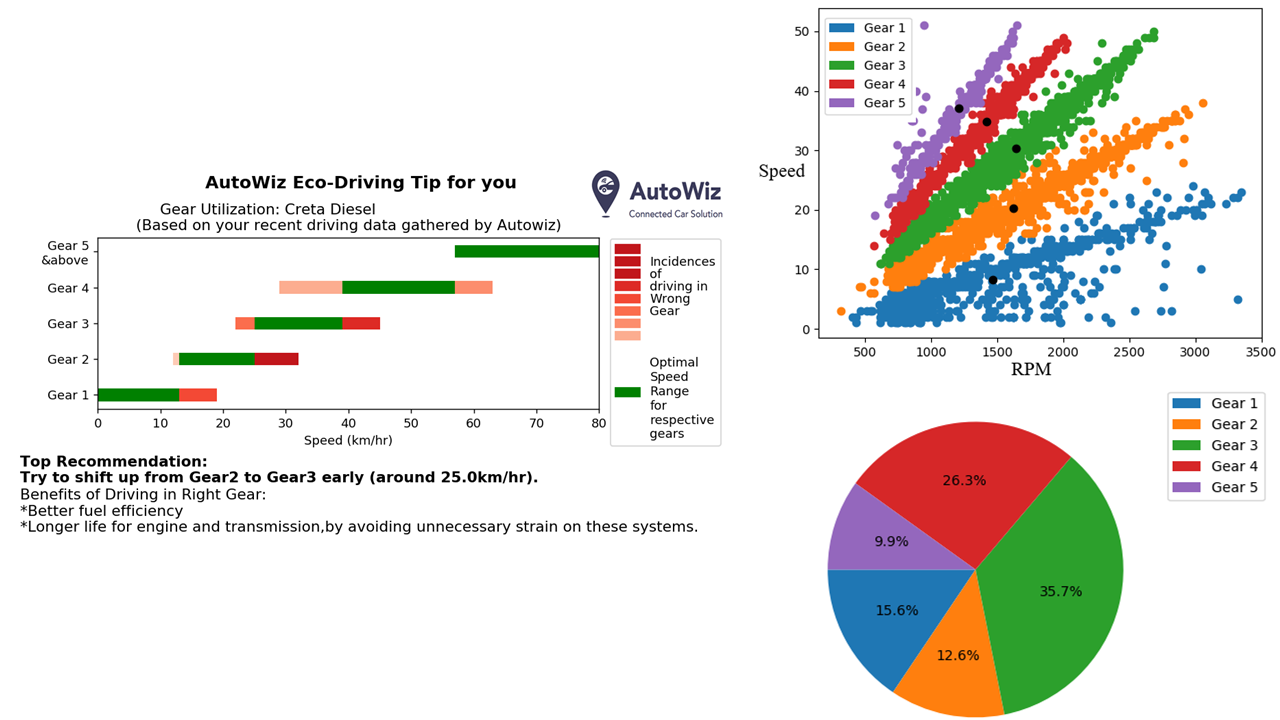
Gear Shift Recommendation
Gear Shift recommendation using OBD-II PID data
Figures- Gear Shift Recommendation Card
- Gear Clusters
- Gear Shift Recommendation Card
-
0D Combustion Modeling of Compression Ignition Engines Using Python
Abstract
The present study develops a single-zone zero-dimensional progressive combustion simulation model using Python programming language for compression ignition engines. The model is capable of predicting in-cylinder pressure, heat release rate, engine performance, and emissions characteristics. The numerical model is experimentally validated using resuts from engine testing for diesel, Pongamia Pinnata biodiesel and diesel-biodiesel blends. The chemical composition of fuel is identified using Gas Chromatography-Mass Spectrometry. The values of power output, mean effective pressure and exhaust oxygen concentration are independently obtained from the numerical model and from the experiments. The engine performance is not significantly affected for biodiesel to diesel blending ratio of up to 30%. A higher oxygen concentration in the exhaust gas is observed with increase in blending ratio. The developed numerical model would be useful in studying the performance and emission characteristics for any alternative fuel with known calorific value and chemical composition.
Modeling Compression Ignition Combustion using Zero-Dimensional Model for Diesel and Biodiesel
using Python for engine performance and emission characteristics.
October 2018 - July 2019
See Publication
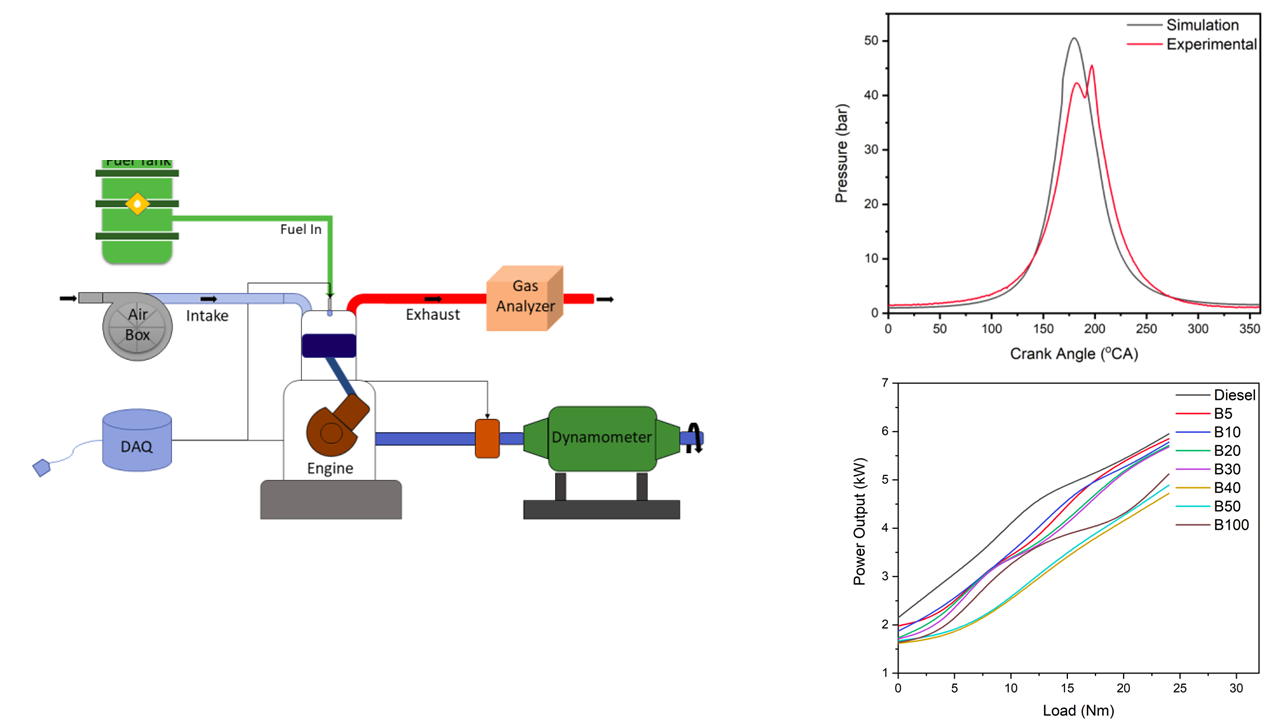
0D Combustion Modeling
0D combustion simulation for IC Engines using Python
Figures- Schematic Diagram of Experimental Setup
- P-Theta Diagram
- Power Vs Load for Diesel, Diesel-Biodiesel and Biodiesel blends
See Publication -
Ethanol Extraction from Bamboo Biomass
Summary
Bioethanol extraction from bamboo biomass comprises of different steps of pretreatment, enzymatic hydrolysis, fermentation, and distillation. Production of fermentable sugars out of biomass also depends on various factors like biomass composition, pretreatment methodology, the efficiency of enzymatic hydrolysis. Primary components of plant biomass are cellulose – main structural polymer, hemicellulose – heteropolymer present along with cellulose, and lignin – complex organic polymer providing key structural strength. The first step in bioethanol extraction is pretreatment, it’s a very crucial step which intends in altering the structural characteristics of biomass for increasing the availability of polymers for hydrolyzing enzymes. This is achieved by the removal of either hemicellulose or lignin fractions from the biomass. Pretreatment methods are mainly classified into physical, chemical, physiochemical and biological techniques which have been established and used in the past decades for bioethanol extraction. Generally, pretreatment involves high-temperature treatment with dilute alkali or acid. Alkali pretreatment remains to be most desirable as it retains cellulose and hemicellulose, meanwhile removing a major portion of lignin in the solid. The second step is enzymatic hydrolysis, during which sugar polymers like cellulose and hemicellulose are hydrolyzed to release free sugar monomers. Enzymatic hydrolysis is preferable over chemical hydrolysis carried out mostly by acid due to its specificity, mild operational conditions, and lesser or no byproduct formation. The third step is fermentation, conversion of fermentable sugars formed after enzymatic hydrolysis to ethanol using microorganisms or biocatalyst.
Setting up production setup for Bio-Ethanol extraction from Bamboo Biomass by Pretreatment,
Enzymatic Saccharification and Fermentation.
June 2018 - July 2019
See Publication
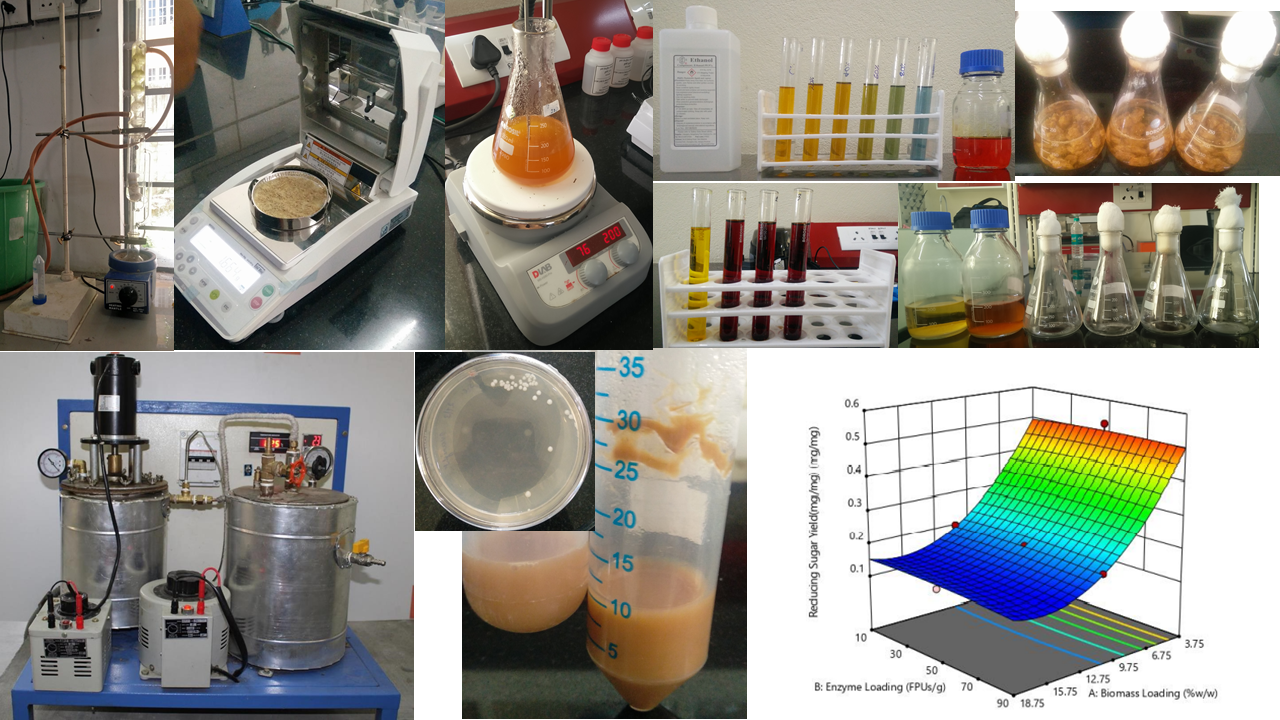
Bioethanol from Bamboo Biomass Production Setup
Setting up production setup for Bio-Ethanol extraction from Bamboo Biomass.
Bioethanol extraction process from Bamboo biomass,- Sample Preparation - bamboo samples where milled, grinded and air dried
- Compositional Analysis - Chemical composition of raw and pretreated biomass were analysed by gravimetric method
- Dilute Alkali Pretreatment
- Enzymatic Saccharification - using cellulase obtained from Zytex Group, Supercut Acid Cellulase. Optimised using Central Composite Design (CCD) and Response Surface Methodology (RSM)
- Ethanol Production – using Saccharomyces Cerevisiae
See Publication